
I recently read through a Hacker News thread discussing the article “Kafka Is Not A Database”, by Arjun Narayan and George Fraser. The opinions behind this topic are fascinating and I enjoyed sifting through comments from both sides of the table. For the purposes of this post, I’ve labeled these two broad groups of thoughts as Team Blue and Team Red.
Team Blue believes that Kafka, a popular streaming platform, has the potential to be the source-of-truth for your data—replacing one of the key responsibilities of conventional databases.
Team Red strongly disagrees.
The following is high-level summary of these opinions.
Kafka As A Database
TL;DR Streams,Events,Kafka
First, a conceptual model of streams:
In computer science, a stream is a sequence of data elements made available over time. A stream can be thought of as items on a conveyor belt being processed one at a time rather than in large batches.
Wikipedia.org
Imagine that you’ve hired an invisible assistant. This assistant’s only responsibility is to record everything you do:
- Wakes up @ 8 am
- Brushes teeth @ 8:35 am
- Begins showering @ 8:40 am
- …
As you go about your day, your assistant meticulously captures your activity and adds new entries into your daily log. This growing log represents a stream of your day-to-day activity. The data elements that comprise the stream are known as events. Once an event is recorded, it is immutable; the fact that you brushed your teeth at 8:35 am yesterday will never change.
While your invisible assistant is following you around and producing new events to your stream, who is consuming them? Anyone who cares! I’m sure your mom would be thrilled to process through your activities and call you if there are any anomalies.
What about Kafka?
Apache Kafka is an open-source stream-processing software platform developed by the Apache Software Foundation, written in Scala and Java.
Wikipedia.org
Kafka is a platform (large set of software tools) that helps programmers work with streams.
Team Blue – Streams Everywhere
Team Blue believes that streams are a natural model for both life and computing. Your users produce a stream of clicks, sign-ups, and orders. Your code produces a stream of logs, metrics, and programmatic events. Team Blue believes that the intuitive nature of streams can lead to intuitive software architectures.
An essential component of any system is the database—a convenient place to read and write whatever you want. How can a stream replace this concept that we are so used to? If streams are a never-ending series of immutable events, then the property of state is the culmination of events up to a certain point in time. For example, the latest state of a database is the culmination of all operations made to that database. In computing, this is referred to as Event Sourcing. This paradigm is very different to how many developers are used to thinking about their data.
Beyond data storage, Team Blue is bullish on the idea of stream-focused architectures in general. Streams work well with microservices, promote loose coupling of systems, and have the potential to create leverage in your software. If you’re thinking about streams, you will inevitably think about Kafka—one of the industry’s leading streaming platforms.
Can you use Kafka as a database? Team Blue says yes.
Should you use Kafka as a database? That’s up to you.
Team Red – You Need Databases
On the other side of the table is Team Red who believes that programmers are making a mistake by replacing conventional databases with Kafka.
Team Red believes that 99% of applications need the features of a conventional database—especially the features handling complex concurrency issues. Many of us use these features and they are critical for the success of our applications. Modern databases are battle-tested and have been iterated on for decades. Team Red believes that the message of “Kafka As A Database” is a dangerous message that leads developers into architectures they’re not equipped to handle.
The People On Each Team
There is no shortage of influential people who align with Team Blue. One notable engineer is Jay Kreps, CEO of Confluent. Confluent is an organization that sells Kafka as a solution to enterprises. There is a direct correlation between using streams and using Kafka; I’m sure Jay has a few extra reasons to be bullish on streams beyond his personal software architecture preferences.
Another influencer aligned with Team Blue is Martin Kleppmann, author of the extremely popular book Designing Data-Intensive Applications. Martin Kleppmann is a researcher who loves the idea of streams. His goal is to educate as many programmers as possible. Martin’s only qualm with Team Red’s opinion is the tone of their blog post. In his own words:
Nice blog post [Kafka Is Not A Database] explaining why the “database inside out” approach is not for everyone. @narayanarjun and @frasergeorgew are right — if you need to maintain constraints before events are written (e.g. not selling more items than you have in stock), it’s easier to use a DB and CDC.
On the other hand, the message is also a bit patronising. It basically says “you’re not clever enough to use an event log correctly — leave database stuff to the experts”. I respectfully disagree: it is good to explore new approaches. Learn about the trade-offs, educate yourself.
Martin Kleppmann
Engineers on Team Red’s side include Arjun Narayan and George Fraser, co-authors of the article which refutes the idea of “Kafka As A Database.” They have decided to put a large, yellow caution sign in front of Team Blue’s message. Team Red has no issue with Kafka or streams; they have an issue with eager developers throwing out their RDMSs and jumping on the stream bandwagon. Their only extra agenda might be to get extra eyeballs on their engineering blogs.
Arguments From Team Blue
The following points are summaries of topics discussed in Martin Kleppmann’s video.
High Integrity Data – Never Deleted
With a database, your information is easily susceptible to being lost. Once your Postgres row is updated, it’s difficult to recover the previous state of that row without introducing custom accountability software. Databases and the records inside them are designed to be mutable. It’s both a great convenience and a great risk. If a table accidentally gets deleted, you might find yourself scrambling to restore your database from a backup. This is particularly painful in production.
On the other hand, if your data exists as a log of immutable events—and that log happens to be retained forever—the history of your changes never runs the risk of being erased. Accounting is a great example of this—accountants balance their books by only appending new entries to their ledgers. An error in a financial transaction is always fixed by another transaction.
Team Blue believes that this characteristic can be an asset to software architectures. As a permanent log of events, data will always have its historical context and can easily be audited. Furthermore, the lack of an “eraser” forces programmers and processes to be held highly accountable for their actions.
One concern of storing all your data in a log is that the size of your logs may become unwieldy over time. Do we really care about how a customer changed their email 3 years ago or do we only care about what it is today? Large Kafka logs can also complicate consumers—catching up from offset 0 may not be so easy. Kafka has implemented features like Log Compaction to mitigate this. However, this is yet another complexity for programmers to manage and debug.
Another trade-off of this architecture is that it can become cumbersome for privacy concerns. There are administrative use-cases (GDPR) which may require you to completely hard delete all of your customer’s personal information from your system. This takes additional effort if the data to be deleted is scattered across logs and storage systems.
Separation Of Concerns – Reading / Writing
Team Blue points out that one of the great conveniences of databases is also one of its greatest challenges. The convenience of databases is undeniable—an easy one-stop shop to read and write anything. The drawback to being a one-stop shop is that you can’t be the best at any one thing, which becomes problematic as you scale.
Conventional databases easy conflate reads and writes, two very different styles of operations. As you scale, the access patterns in your software will inevitably force you to optimize for a certain set of operations. If an operation-specific optimization is done in a centralized location, it will likely degrade the performance of other operations in that location. If you optimize reads, you complicate writes—and vice versa.
One of the first steps in optimizing SQL reads is to begin denormalizing (duplicating) data across various tables. Once your data is duplicated, queries require less joins and respond faster. However, the drawback of denormalization is that it creates additional complications on the write pathway. Programmers need to remember to update and synchronize the duplicated data across multiple tables.
This pattern grows in complexity as you scale. If denormalization isn’t getting you the required read performance, the usual next step is to introduce a cache in front of your database. A cache is extremely convenient and can be designed to precisely answer the questions your clients are asking. However, as many programmers are intimately aware of, maintaining a cache is never easy. You now to need synchronize writes across network boundaries, worry about distributed transactions, and debug subtle invalidation issues.
Going back to our make-believe example, my assistant only has one responsibility—log my daily activity. One day, I decide that I want to look back in time to see how my activities are categorized. Unfortunately, I can’t ask my assistant this question because it’s too specific; all he knows how to do is produce events. To get insights on my activity, I need to hire a category manager to consume my activity stream and categorize everything. Assuming my manager is caught up, she’ll be able to immediately and accurately answer any question I have regarding my activity categorization.
With streams, there is a clear separation of concerns between readers and writers. Producers only worry about producing. Their access pattern is straightforward and lightning fast. Consumers only worry about consuming. They can be programmed to handle any use-case and never have to worry about affecting the performance of their producer counterparts. How fast you’re able to push updates to Elastic Search is completely independent from how quickly Kafka can write to a file.
For Team Blue, this separation of concerns is an advantage of streams. Databases are convenient, but they conflate concerns and quickly create performance trade-offs as you scale.
Easier Caching
One of Martin Kleppmann’s most interesting ideas is that you can get “Fully Precomputed Caches” with stream architectures. A common setup for Kafka consumers is to process logs in order to create various materialized views. A materialized view has a similar end goal as a cache—provide a precomputed view of the data that is useful for a client. However, the way in which they are maintained is drastically different.
With a materialized view, the write pattern is incredibly simple. The materialized view is created by simply processing through the log of events and updating the view accordingly. The process is straightforward, but potentially time-consuming. On the other hand, caches often have complex and error-prone write patterns. Logic to update and invalidate caches is often scattered around business logic, executed randomly depending on how customers use an application.
The concept of “warm vs. cold” caching also goes away with materialized views. If a materialized view is fully created (completely “caught up”), then it represents the complete state of the data. There is never a cache miss because a complete materialized view is completely hot by definition. Instead of worrying about cold starts and how to properly warm up a cache, programmers can create materialized views offline and start using them whenever they’re ready.
Using materialized views for convenient caching comes with a cost. Materialized views are separate pieces of infrastructure that need to store their own data, scale, and be reliable. Loose coupling of systems sounds nice, but the added operational overhead is never trivial. For small applications, this may be overkill. Don’t forget the conveniences of a database—you can query it whenever you want. A Kafka log doesn’t doesn’t respond very well to SQL. Querying a database is much simpler than setting up new consumers and ensuring materialized views are synchronized.
Arguments From Team Red
“Streams Everywhere” Is A Dangerous Message
Team Red believes that the ideas behind “Streams Everywhere” are hurting the software industry by causing eager engineering organizations to adopt streams without understanding their consequences. George comments:
We’re trying to address a real problem that is happening in our industry: VPs of eng and principal engineers at startups are adopting the “Kappa Architecture” / “Turning the Database Inside Out”, without realizing how much functionality from traditional database systems they are leaving behind. This has led to a barrage of consistency bugs in everything from food-delivery apps to the “unread message count” in LinkedIn. We’re at the peak of the hype cycle for Kafka, and it’s being used in all kinds of places it doesn’t belong. For 99% of companies, a traditional DBMS is the right foundation.
George Fraser
George’s points are valid. Software engineers have a tendency to adopt new and shiny objects without fully understanding them. Just because Kafka is trending, it doesn’t mean you need to solve every problem with it. Engineers need to be responsible, understand trade-offs, and choose technologies that fit their requirements.
Be careful of arguments that appeal to popularity. If databases are the correct solution for 99% of applications, what about the other 1%? Your application could be in that minority and may deserve a novel architecture. Team Blue argues that you should find out the answer for yourself. There’s a time to follow conventional wisdom and there may be a time to forge your own path.
Losing Critical Database Features
Team Red warns that many critical features will be lost if you forgo a database in favor of logs. In particular, features that help enforce data integrity are extremely useful and are extremely difficult to replicate. These features include foreign key constraints, the atomic (all-or-nothing) nature of transactions, and complicated isolation techniques that help mitigate concurrency issues. Arjun of Team Red writes:
In principle, it is possible to implement this architecture in a way that supports both reads and writes. However, during that process you will eventually confront every hard problem that database management systems have faced for decades. You will more or less have to write a full-fledged DBMS in your application code. And you will probably not do a great job, because databases take years to get right. You will have to deal with dirty reads, phantom reads, write skew, and all the other symptoms of a hastily implemented database.
Arjun Narayan
Arjun also has valid concerns. For a majority of applications—especially the smaller ones—these data integrity features are convenient and may be essential for your application’s success.
Even though databases are wonderful, they are not without their own bugs. Kyle Kingsbury’s Jepson work showcases discrepancies between how databases claim to behave versus how they actually behave under stressful conditions. In his book, Martin Kleppmann also mentions that programmers may place too much trust in databases. This has consequences with the verification and integrity of data. Like any other software, Postgres and MySQL aren’t perfect.
Arjun’s argument assumes that your application needs to maintain high-integrity data at all times. This is not always the case. Large amounts of data integrity checks imply expensive write operations. For large-scale systems, programmers may choose to purposefully loosen—or fully remove—these checks in favor of increased write throughput. These highly-available systems allow bad data, but are programmed to be eventually consistent so customers can still have good experiences. These trade-offs are explained further in the famous Amazon Dynamo Paper.
The Complexity Of Asynchronous Data Integrity
In one of his presentations, Martin Kleppmann reviews the ACID properties of a database transaction and how they can be implemented with a stream-based architecture:
If your system has strict requirements for validating data, you need to be very thoughtful when designing a stream-based architecture. As shown in the video, the complexity of ensuring all your customers have unique email addresses with streams is significantly more involved than adding a uniqueness constraint to a database column.
With streams, basic features that we take for granted become new responsibilities for your code and operations. You’ll need to separate the intent to write versus committing the write. You’ll need to serialize consumption of specific streams while parallelizing others. You’ll consume events only to immediately produce other events. All these complexities, combined with the fact that the software industry is extremely inexperienced with stream architectures, should give developers pause before choosing to adopt any of these new paradigms.
Kafka Alongside A Database
Team Red proposes that Kafka shines when used alongside a database.
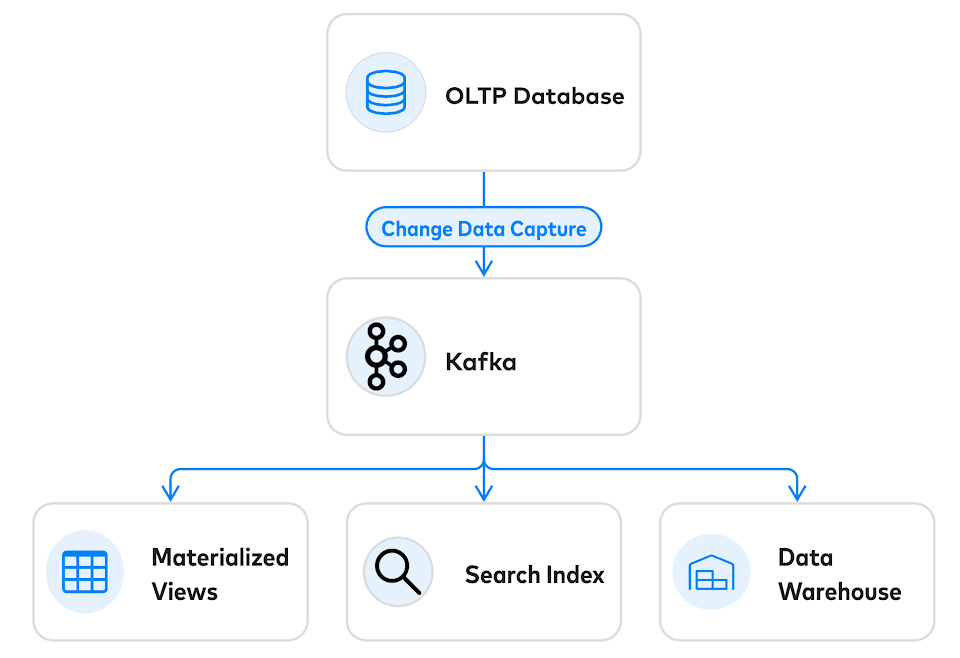
In the article, Team Red argues that the data integrity features of databases perform the crucial functionality of “access control.” A common architecture setup is to use Kafka alongside a Change Data Capture (CDC) system. In the diagram above, there are three basic steps:
- User requests hit the application and kick off transactional write operations to the database.
- If all the checks look good, the writes land and update the database.
- CDC reacts accordingly, translates the valid changes into valid events, and ships them off to Kafka to be consumed.
One of Kafka’s main highlights is its ability to handle a large number of writes. The write pattern is very simple—everything goes to the end of the log. With conventional databases, transactions need to be isolated, indexes need to be updated, and constraints need to be checked. This means that writes can be very expensive. If your application is bottlenecking around expensive writes, the conventional database may hold you back. Team Red doesn’t mention that putting a database in front of Kafka would cause you to miss out on one of Kafka’s best qualities.
When hitting scaling issues with writes, it’s common for engineers to begin handling writes asynchronously. If you’re designing a system with known, large-scale write requirements, I’m sure Team Blue would recommend you go with streams.
So, Kafka As A Database?
There is never a one-size-fits-all solution in software development. The discussions surrounding “Kafka As A Database” are deep and I encourage everyone to dig further into the opinions of both Team Red and Team Blue.
I personally have never used a Kafka log as the source-of-truth for my data. Stream-focused paradigms are fascinating to read about and I conceptually understand their benefits, but I’m personally a little wary of their practicality in large software organizations—especially ones with a wide range of opinions. Software development is hard enough as it is, even when trying to go “by the book.”